
🚀 이번 포스팅 키워드
- Pooling, No Pooling
- Connection Pool
- Connection
- Socket
💬 포스팅 흐름 요약
No Pooling과 Pooling을 iftop 툴을 이용해서 두 실행 속도를 비교하고 있었습니다.
Connection Pool을 이용하느냐 마느냐에 차이였고 Connection 생성 비용이 비싸서 그렇다는 것은 많이 들어왔습니다.
데이터베이스 서버와 연결을 미리 해놓고 계속해서 재사용하는 말을 수도 없이 들어왔지만 실제로 눈으로 확인해보지 않았으니 이번 기회를 통해서 한 번 디버깅해보면서 연결되는 부분을 찾고 그 흐름을 파악할 수 있었습니다.
No Pooling
Connection Pool을 사용하지 않고 요청이 들어올 때마다 새로운 Connection을 생성합니다.

iftop 를 이용해서 NIC 트래픽을 확인해본 결과 11.7MB/8.64Kb/5.18Mb로 전송하고 있음을 볼 수 있습니다.
테스트를 실행했을 때 실행 시간은 6846ms가 나왔습니다.
실행 시간 : 6846ms이제 Connection Pool을 이용했을 때와 비교해봅시다.
Pooling
Connection Pool을 준비합니다.
HikariCP를 이용할 것이여 풀 사이즈는 1로 두고 실험을 진행하겠습니다.
풀 사이즈를 1로 둔 이유는 No Pooling 에서 실험했을 때
Connection을 한 스레드로만 계속해서 순차적으로 진행하도록 했기 때문에 이와 같은 환경을 만들어 비교하기 위해서 입니다.
final HikariConfig config = new HikariConfig();
config.setJdbcUrl(container.getJdbcUrl());
config.setUsername(container.getUsername());
config.setPassword(container.getPassword());
config.setMinimumIdle(1);
config.setMaximumPoolSize(1);
config.setConnectionTimeout(1000);
config.setAutoCommit(false);
config.setReadOnly(false);
final HikariDataSource hikariDataSource = new HikariDataSource(config);
이제 테스트 코드를 실행해보고 NIC에 나오는 트래픽을 모니터링 했습니다.

평균 전송량은 7.55Mb/5.06Mb/1.80Mb가 왔으며
Connection Pool을 이용했을 때 실행 시간은 1415ms가 나왔습니다.
실행 시간 : 1415ms이전에 Pooling을 이용하지 않았을 때의 6846ms에 비해서 시간이 크게 감소할 것을 확인할 수 있습니다.
여기까지만 봐도 실제로 Connection Pool을 이용했을 떄 훨씬 더 짧은 시간에 동일한 데이터를 송수신할 수 있음을 알 수 있습니다.
Pooling이 더 효율적인 이유
Connection 비용이 크기 때문에 미리 Connection들을 준비해놓고 재사용하는 방식이 바로 Connection Pool 입니다.
Pooling 방식은 Connection을 사용한 후에 객체를 해제하는 것이 아닌 객체를 반납하고
이후에 다른 사용자가 해당 Connection을 재사용할 수 있기 때문에 훨신 효율적입니다.
그렇다면 Connection를 생성할 때 어떤 작업들을 진행하기에 비용이 비싸다고 하는걸까요?
아래 테스트에서 getConnection()을 디버깅해서 No Pooling 을 이용했을 때
Connection 을 생성할 때 어떤 일이 있길래 그렇게나 비싸다고 하는지 알아봅시다!!

datasource.getConnection() MySQL DataSource를 생성합니다.
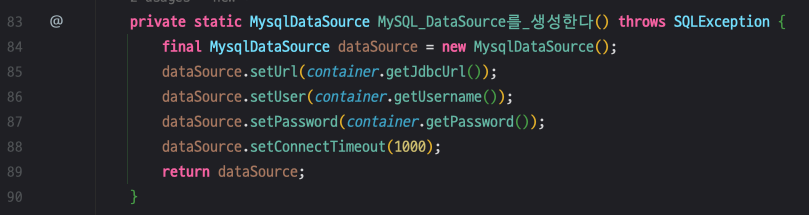
MysqlDataSource에서 Connection을 가져오기 위해 getConnection() 메서드를 호출합니다.
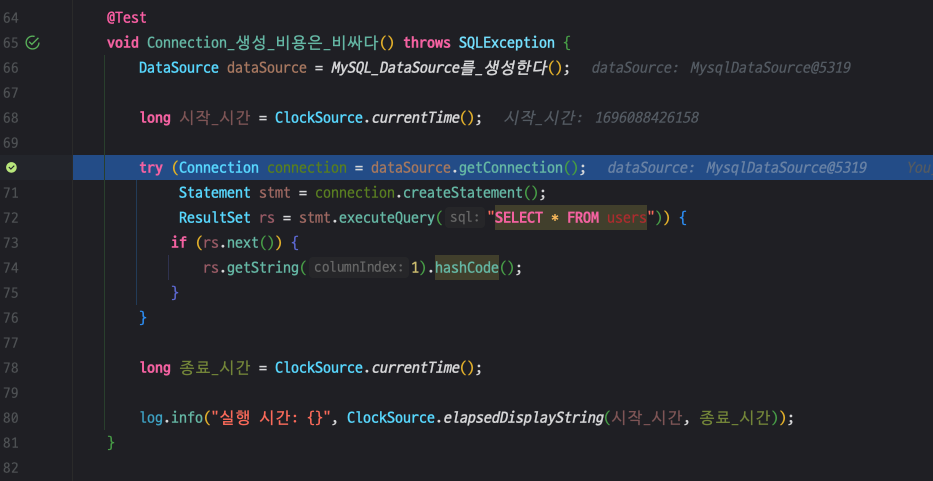
내부로 들어가면 MysqlDataSource에서 다시 getConnection() 내부 메서드를 호출하고 있습니다.

MysqlDataSource의 getConnection() 내부 구현을 보면 아래와 같습니다.
Properties를 가져오고 있는 것을 볼 수 있습니다.
어떤 속성들을 가지고 오는지 exposeAsProperties() 메서드 구현으로 들어가보겠습니다.
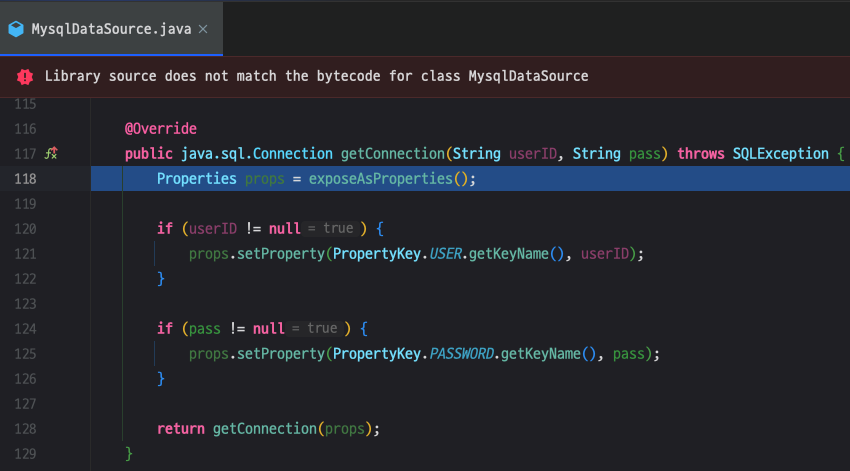
exposeAsProperties() 내부를 보면 Properties 객체를 생성한 후에 for문을 돌려 필요한 정보를 주입하는 것을 볼 수 있습니다.
이 때 Properties 는 java.util.Properties 입니다.
for문을 보면 PropertiesDefinitions.PROPERTY_KEY_TO_PROPERTY_DEFINITION의 키 값으로 속성 값을 가져오는 것을 볼 수 있습니다.
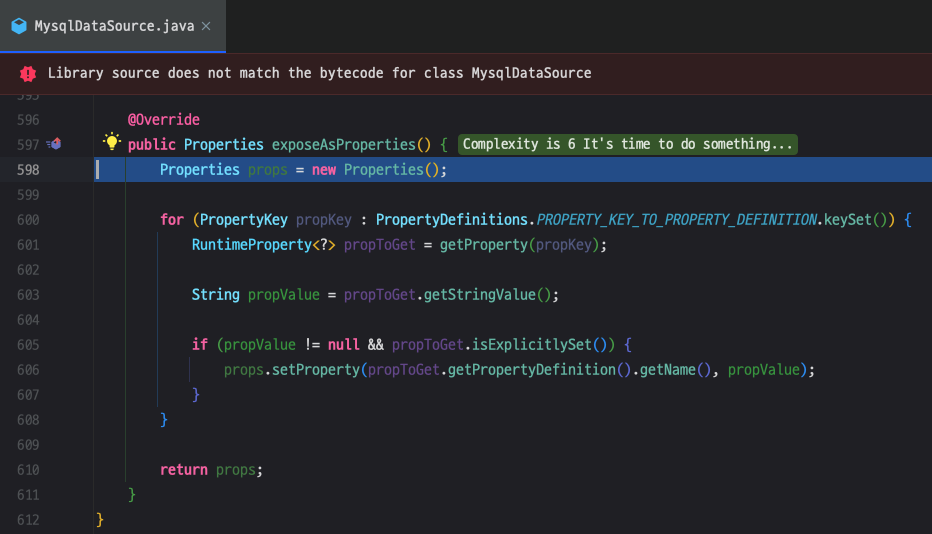
여기서 비용이 크다고 느껴지는 것은 바로 키(key) 값의 사이즈가 216 인 것입니다.

키 값들의 이름을 보면 모두 Connection 에 필요한 정보입니다.
너무 많은 정보들이 있어 하나하나 설명하지는 않겠습니다.
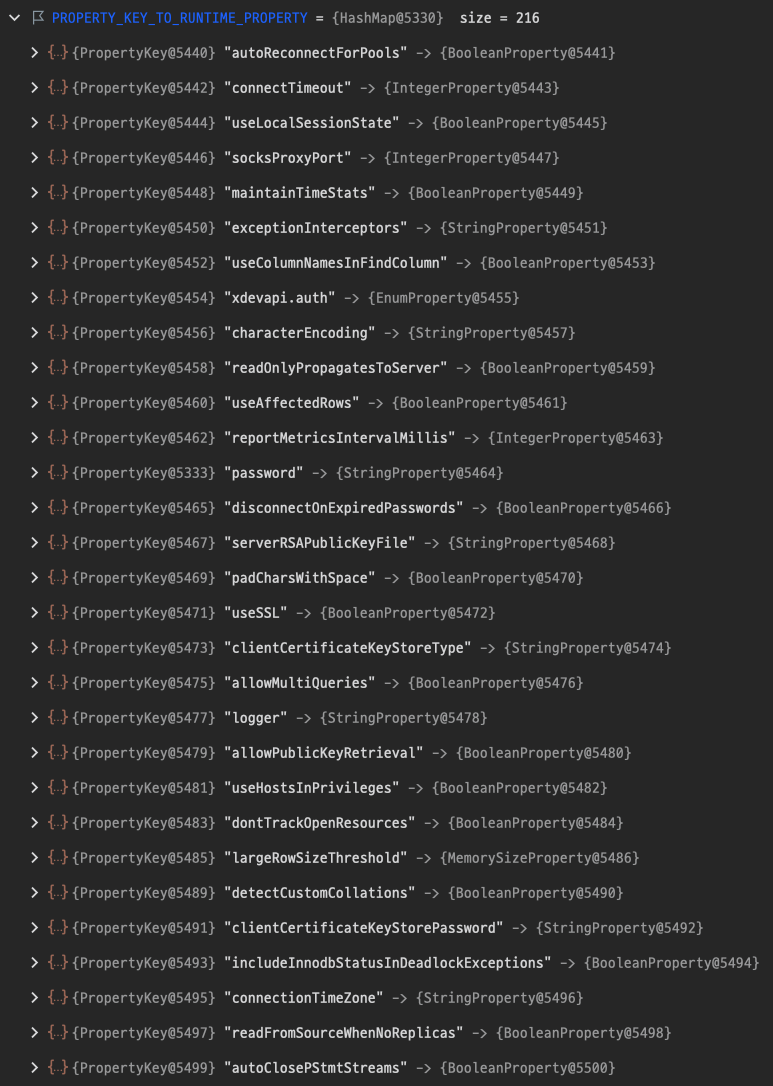
그래도 그냥 지나가기는 아쉬우니 for문 내부 동작을 하나만 봐보도록 하겠습니다.
가장 최상단에 있는 autoReconnectForPools를 보겠습니다.
propKey가 authReconnetionForPools라고 했을 때 getProperty(propKey) 메서드를 호출합니다.

getProperty(propKey)내부 구현은 아래와 같습니다.

propKey 키(key)로 매핑된 값(value)을 가져오게 됩니다.
이 때 값(value)은 BooleanProperty 타입으로 내부 값은 false인 것을 보실 수 있습니다.
현재 실험은 No Pooling 일 때 사용자가 데이터베이스에 접근하기 위해 Connection을 생성하는 흐름을 보기 위함이었습니다.
그리고 키(key)였던 propKey는 autoReconnectionForPools였고 매핑된 값(value)로 false가 나온 것을 확인했습니다.

친절하게도 내부 description으로 현재 값이 어떤 것에 대한 의미인지 설명도 있습니다.
이런 식으로 Connection을 생성하기 위해서는 수많은 속성들을 읽고 주입해야 합니다.

하지만 이 정도의 속성을 읽기 때문에 비용의 차이가 크다고는 할 수 없습니다.
저희는 118 라인에 exposeAsProperties() 만 봤습니다.
이제 두 조건문(if)를 넘기고 128 라인에 getConnection(props)내부 구현을 봐보도록 합시다.
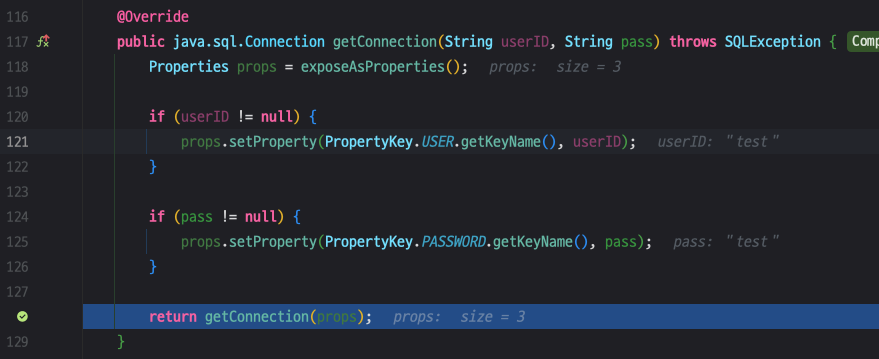
위에서 모았던 정보(props)를 가지고 연결을 진행하게 되는 내용입니다.
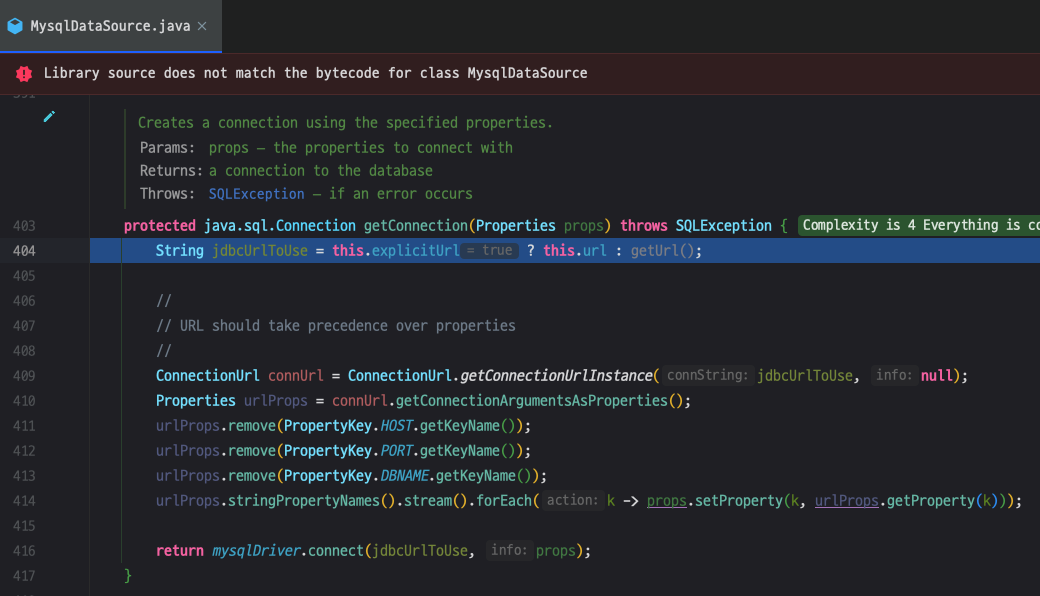
409라인에 ConnectionUrl.getConnectionUrlInstance(String connString, Properties info) 를
호출해서 데이터베이스에 연결할 정보들을 파싱하여 ConnectionUrl 객체를 반환합니다.
- connString : jdbc:mysql://localhost:56488/test
- info : null
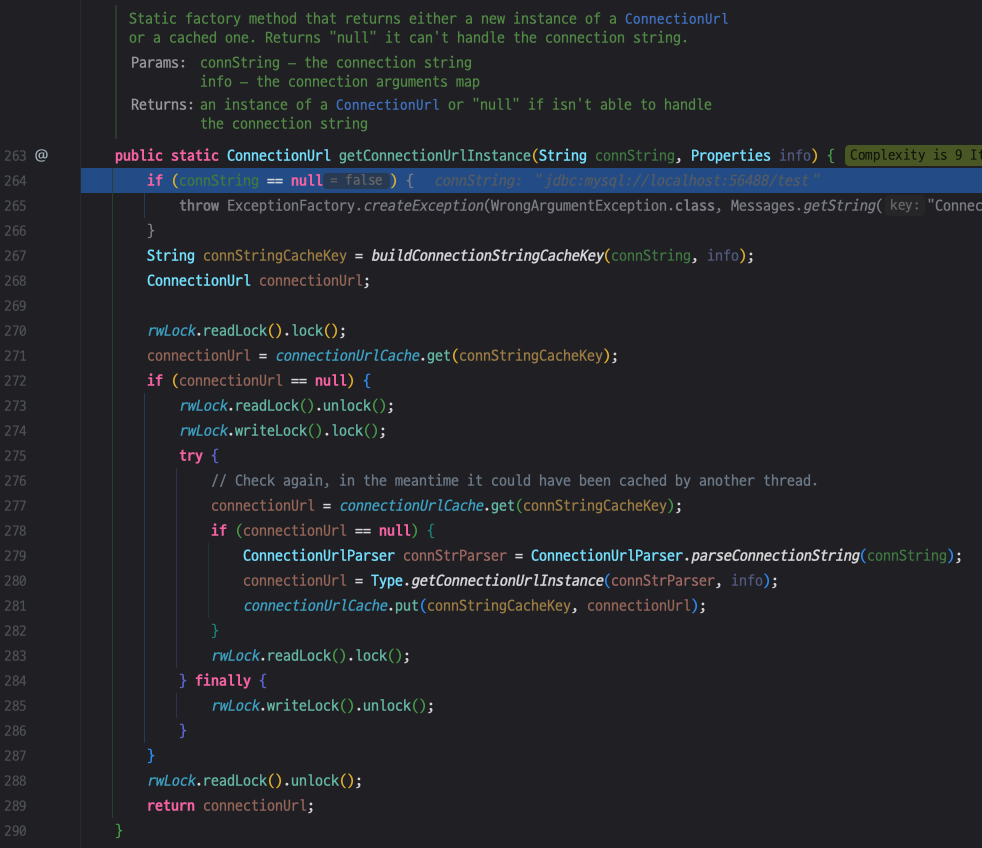
데이터베이스에 연결할 정보를 잘 정리했다면 이제 그 정보를 사용해서 연결을 진행합니다.
416 라인에 mysqlDriver.connect(jdbcUrlToUse, props)를 호출하는 것을 볼 수 있습니다.
mysqlDriver.connect() 내부로 들어가보겠습니다.
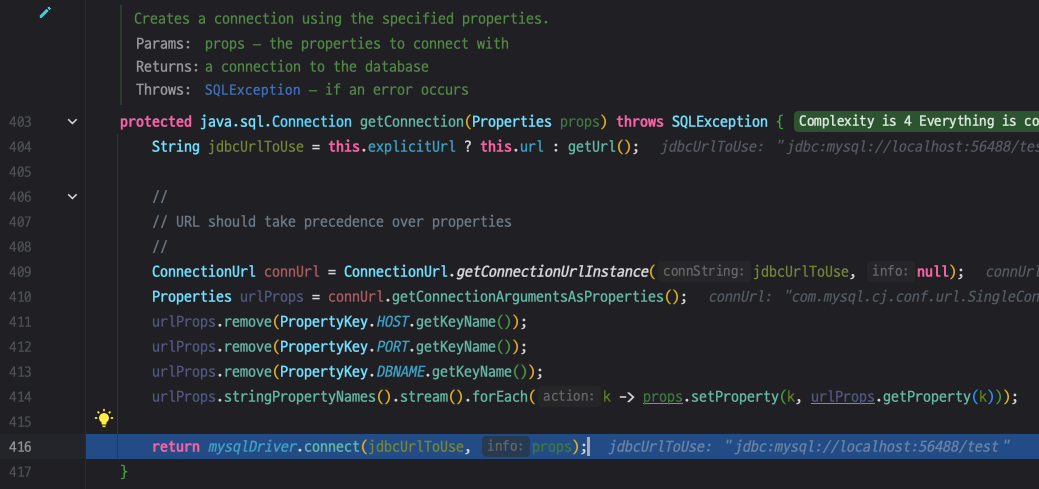
com.mysql.dj.jdbc.NonRegisteringDriver에 구현된 connect() 메서드입니다.
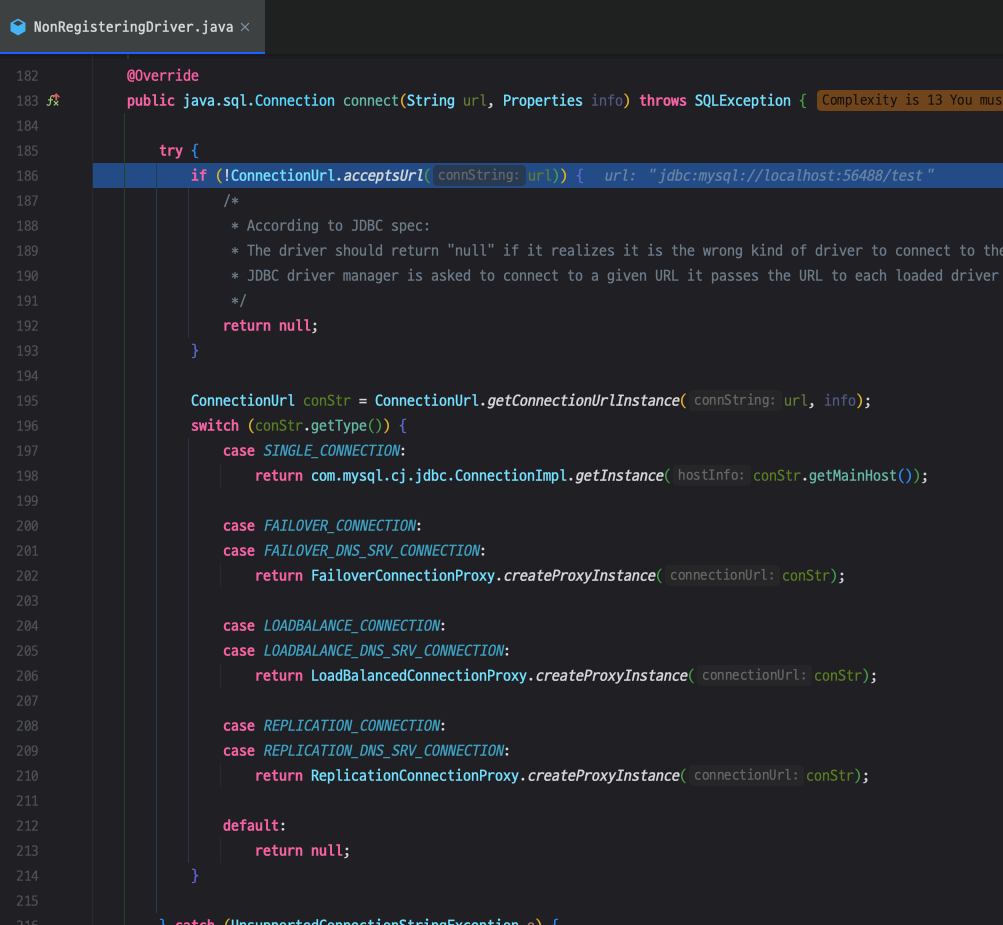
클래스명을 보면 드라이버를 제대로 찾지 못했나싶지만 이 구간이 필요한 드라이버를 찾는 구간입니다.
NonRegisterDriver 문서를 보면 DriverManager를 통해서 찾아올 것이라고 설명하고 있습니다.
다시 connect() 메서드로 돌아오겠습니다.
먼저 ConnectionUrl이 유효한지 확인합니다.
유효하다가면 아래 swich문을 진행하게 됩니다.
현재 테스트 환경에서 로드밸런스, 리플리케이션 등을 사용하지 않으므로 ConnectionUrl은 SINGLE_CONNECTION입니다.
그리고 ConnectionImpl.getInstance() 으로 보아 커넥션 인스턴스를 생성한다는 것을 알 수 있습니다.
getInstance() 내부로 들어가봅시다..!
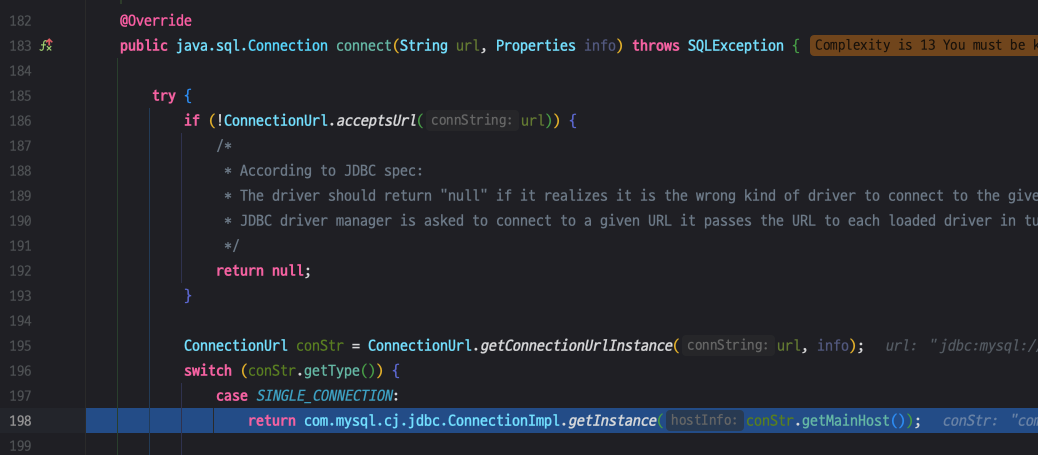
예상한대로 주석으로 커넥션 인스턴스를 생성한다고 설명하고 있습니다.
커넥션이 왜 비싼지는 알기 위해서는 조금 더 안으로 들어가봐야할 거 같습니다.
네. new ConnectionImpl() 내부로 들어갑시다.
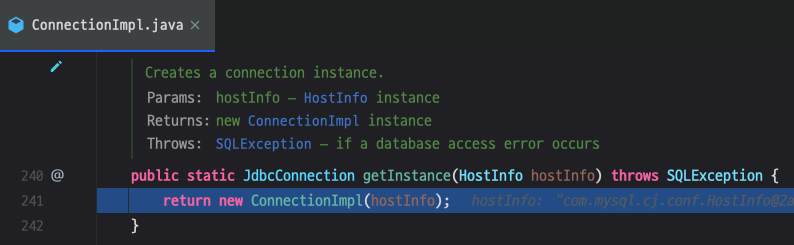
여기서는 조금 더 확실하게 MySQL 서버 커넥션을 생성한다고 설명합니다.
앗, 그렇다면 이전에는 mysql 패키지가 아니었나 싶지만 다 mysql 패키지 내부에 존재하는 것들 이었습니다.
- com.mysql.cj.jdbc.NonRegisterDriver
- com.mysql.cj.jdbc.ConnectionImpl

ConnectionImpl 생성자 소스 코드가 길어서 위에서는 간단하게 잘라서 주석을 보여드렸습니다.
실제 소스 코드는 아래보다 조금 더 길지만 다 담지는 못했습니다.
호스트, 데이터베이스 속성들이 나열되어 있습니다.

제가 찾고 싶었던 가장 중요하다고 생각되는 부분만 아래에 올리겠습니다. (위 사진에는 안나왔습니다.)
같은 생성자 내부 코드로 374 라인 ~ 469 라인까지 이어지는 코드입니다.
바로 448 라인에 createNewIO()입니다.
IO 라는 단어를 보니 데이터베이스와 데이터를 읽고 쓸 수 있게 연결해주는 부분이 있음이 느껴집니다.
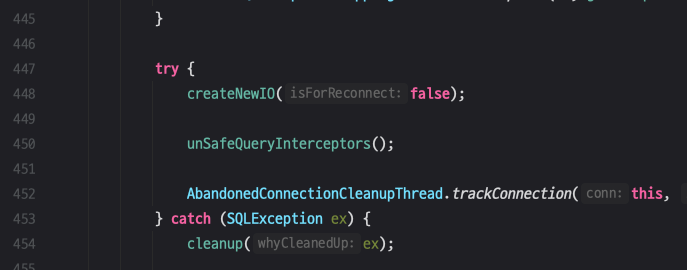
createNewIO() 내부 코드에 818 라인을 보면 connectOneTryOnly()가 있습니다.
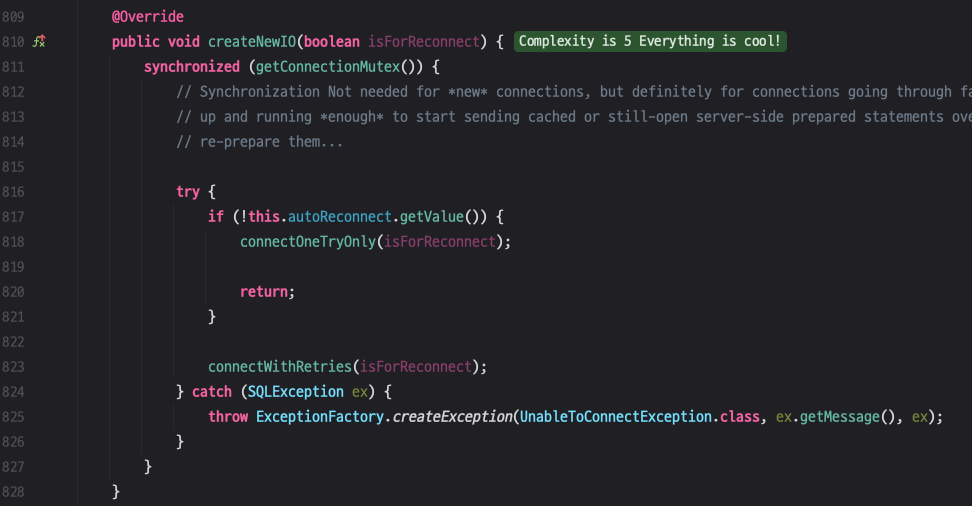
connectOneTryOnly()에 들어가면 948 라인에 session.connect()를 볼 수 있습니다.
- 이 때 session은 com.mysql.cj.NativeSession 이다.

세션에 연결한다.. 그렇습니다.

통신하려면 소켓이 필요합니다.
데이터베이스도 마찬가지로 통신하기 위해서는 소켓을 연결해야 합니다.
아래 NativeSession.connect() 내부에서 SocketConnection을 생성한 후 소켓과 데이터베이스 서버가 연결됩니다.
그리고 데이터베이스와 소통하기 위한 프로토콜을 만들어 통신을 진행하게 됩니다.

Connection 생성 비용은 비싸다.
위에서 Connection을 생성하면 어떤 작업들이 진행되는지 간단하게 디버깅 해봤습니다.
데이터베이스 연결에 필요한 속성들을 확인하는 것은 큰 영향을 줄거 같지는 않습니다.
문제는 소켓입니다.
데이터베이스 서버와 통신하기 위해서는 소켓이 필요합니다.
이러한 소켓을 사용자가 필요할 때마다 생성하고 사용이 끝나면 제거하는 작업은 반복적이며 속성들을 확인하는 작업보다 훨씬 더 큰 작업입니다.
즉, Connection Pool을 사용하지 않으면 계속해서 소켓을 열었다가 닫아야하는 비용 또한 감당해야 한다는 것을 알게 되는 디버깅이었습니다.
'💽 데이터베이스' 카테고리의 다른 글
| 데이터베이스 인덱스 맛보기 (1) | 2023.12.09 |
|---|---|
| 태그 자동 완성 검색 기능에 인덱스를 걸어보자 (0) | 2023.09.17 |